Toward Contextual AI/ML
Robert Pilgrim & Andy Bevilacqua
1 Introduction
In 2011, we watched IBM’s Watson decisively defeat the two top-ranked Jeopardy! players, only to end the game referring to Toronto as a U.S. City.[1] Artificial Intelligence (AI) continues to astound us with successes that exceed human performance and shock us with failures that are less than child-like. With the continuing incursion of AI into all aspects of our lives, there is a growing need to as-sure that these machine-generated solutions are correct, explainable, and non-life-threatening. When AI is confined to game bots and software simulations, cata-strophic errors can be trivial or even humorous. When AI is controlling real-world systems, even small errors can be catastrophic. In disciplines affecting human safety, studies have resulted in regulations, and recommendations for standards and practices for the development and use of AI and Machine Learning (ML).
In 2018, the National Defense Research Institute (NDRI) of the RAND Corporation carried out a study of the Department of Defense (DoD) position on AI as requested by the director of the Joint Artificial Intelligence Center (JAIC). The objectives of this study were threefold: To assess the level to which AI is relevant to DoD operations; determine DoD’s posture relative to the use of AI; and to provide recommendations to the various stakeholders to enhance DoD’s posture in AI. The importance of Verification and Validation as well as the lack of data and standardized approaches for Test and Evaluation of AI systems (collectively referred to as AI VVT&E) were raised repeatedly. The RAND report summarizes,
The current state of AI VVT&E is nowhere close to ensuring the performance and safety of AI applications, particularly where safety-critical systems are concerned. Although this is not a uniquely DoD problem, it is one that significantly affects DoD.[2]
In a collaborative white paper from the Association for the Advancement of Medical Instrumentation (AAMI) and the British Standards Instrumentation (BSI) Group, the authors differentiate between bounded Machine Learning (ML) models and Continuous/Adaptive ML Models. Their concerns are centered on systems that automatically modify their own algorithms or change their outputs based on self-identified improvements. With respect to patient trust, they point out,
…there is danger in over-trusting AI—believing whatever the technology tells us, regardless of the performance limitations of the system. The propensity to trust too much is exacerbated by the current amount of hype that is setting unrealistically high expectations of the technology’s competence.[3]
Recent fatal accidents involving autonomous vehicles have drawn the attention of State and Federal regulators. At this time, the U.S. Congress has delayed voting on a bill to expand exemptions for DOT non-compliant (e.g., experimental) vehicles on public roads beyond the current limit of 2,500.[4]
It is in everyone’s best interest that private companies and researchers who are testing and deploying safety-critical AI/ML systems work diligently to justify the trust being placed in them by the public. Those with the greatest understanding of the technology are the most well-suited to validate it.
This paper presents a pragmatic approach to verifiable Artificial Intelligence (AI) and Machine Learning (ML) based on a collaboration and consensus among multiple agents. It addresses the need for more precise monitoring of information exchanged at the boundaries between the real-world and the digital domain. It suggests the importance for a willingness to share and discuss shortfalls in order for developers to ensure the deployment of safe autonomous AI/ML applications.
2 Approach
Validation has been the central part of our AI research approach since the mid-1990’s. In a series of examples, we show the value of integrating software agents that monitor the actions and decisions in an AI/ML system at the outset, rather than conducting AI VVT&E after the fact. We also demonstrate the importance of monitoring and quantifying the level-of-fidelity of the measurements being presented to and received from an AI/ML application.
We precede these examples with a discussion of our general approach to applying agents to monitor the information crossing the boundary between the real-world and the digital domain as depicted in Figure 1.
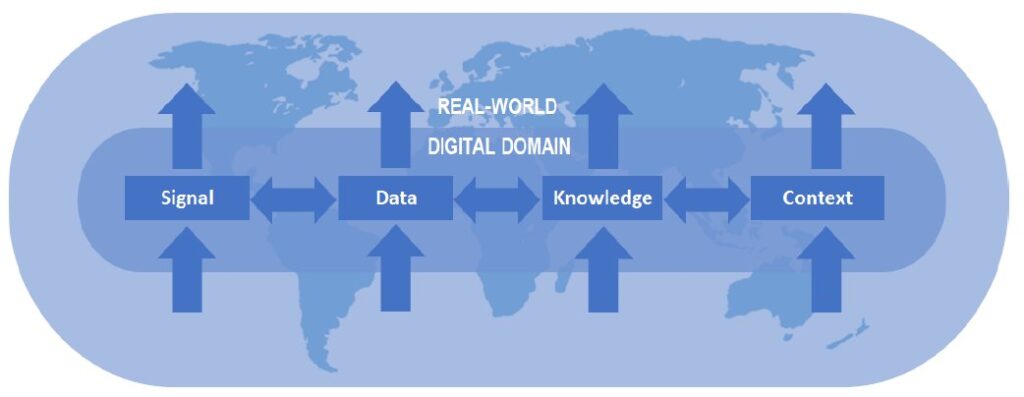
An AI/ML system operates at four distinctly different levels. The leftmost block of this diagram represents Signal level processing. Input at this level is accomplished by electronic sensors that convert physical phenomena into digital values. Other electronic devices such as actuators convert digital values into light, sound, motion, or other phenomena relevant in the real-world. It is important to understand what information crosses this boundary and what is lost. The detail of digitization is well documented and will not be elaborated upon here. However, it is important to note that time does not cross this boundary. If time is important, it must be included as a tag or index attached to data. In the case of video, time rate is set by a frame rate, but the time when the video was recorded is a separate tag.
Digital images are typically tagged with date, time, and location. It is less common to include the orientation of the camera or its optical properties. In our examples, we will demonstrate that this information can be used to enhance situational awareness for an AI system by providing the context that is lost at the boundary between the real-world and digital domains.
The Data level represents records of a symbolic or syntactic nature. Input at this level could be direct keyboard entry or any form of grid data (think spread-sheets). Most of Pattern Recognition, Classification and Clustering involve processing of grid data. A large part of data analytics activities involves manual or automated processing at this level. To press the point of the potential value of in-formation lost at the boundary, we note that the timing between keystrokes of data entry can be a useful biometric to verify the identity of the person typing.
The semantic relationships between entities are captured and represented at the Knowledge level. For example, the “is-a” relationships are encoded at this level. We use conceptual graphs (CGs) as depicted in the GUI CG Editor in Figure 2, to build these boundary monitoring agents.
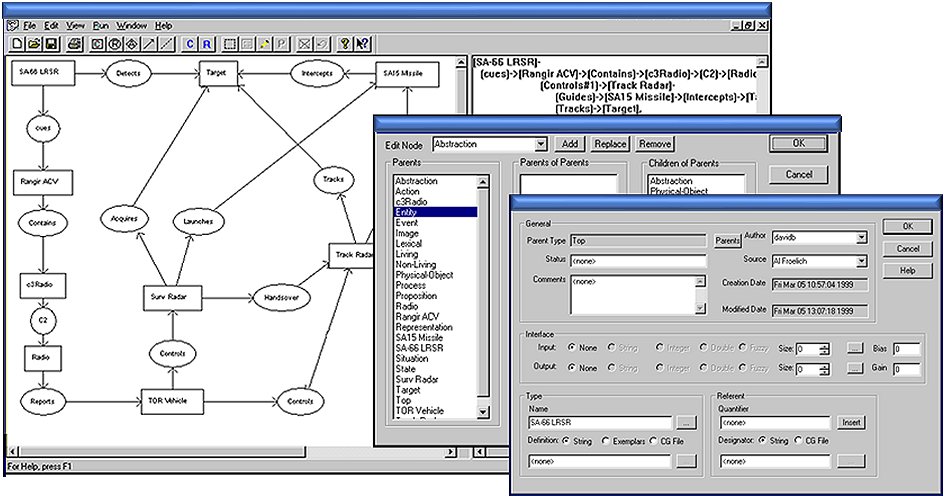
Fig. 2 Conceptual Graph Knowledgebase Editor
When machine learning is used to extract knowledge from data, conceptual graphs help verify entity relationships for known models. Conversely when one or more CG monitoring agents detects an entity value out of range or an unrecognized pattern, the anomaly can be reported and handled. The particular actions dealing with anomalies depends on the application.
We include the Context level to represent an AI system that possesses general, rather than simply expert, knowledge. While boundary monitoring agents can be unique to a particular application, we recognize that it may be feasible to use agents to enforce fundamental rules that apply to all situations. These universal agents can be based on laws of physics, mathematical theorems, or rules of logic and geometry. Another type of general or common-knowledge agent is an anomaly detector. Such an agent uses unsupervised learning to establish nominal behavior and then reports deviations from this baseline. Contextual AI/ML is achieved when a sufficient number of universal monitoring agents are combined to form a collaborative network which is able to “understand” queries and to explain its decisions or actions. This is a major goal for AI VVT&E.
3 Examples of Using Multiple Agents
In the following examples we show some notable steps in the development of this multiple-agent boundary monitor approach to verifiable AI. We track the interaction of specific agents and their use in a variety of applications. In the first example, geometric and orientation agents are used to simplify the process of sensor fusion. Next, the training of neural networks to interpret the visible characteristics of battle damage on tanks is bounded by monitoring agents to ensure only pertinent features are being considered. In the last example, geometric and orientation monitoring agents are combined with multiple AI machine vision methods to produce a contextual hazardous terrain detection system.
3.1 Sensor Fusion
In the first example we review of our approach to a problem in sensor fusion.[5] In this application we were tasked to match observations of point-sized objects in a cloud viewed by multiple imaging sensors separated from each other in three-dimensional space. The purpose of sensor fusion was to be able to deter-mine the three-dimensional coordinates of the objects in the cloud. The objects appeared in the images as patterns of dots as shown in Figure 3.
As these were optical sensors, we had no direct measurement of the distances to the objects from the sensors. We expected this to be a “simple” geometry problem with pattern matching. However, due to the large number objects and their close spacing, the problem turned out to be a bit more involved.
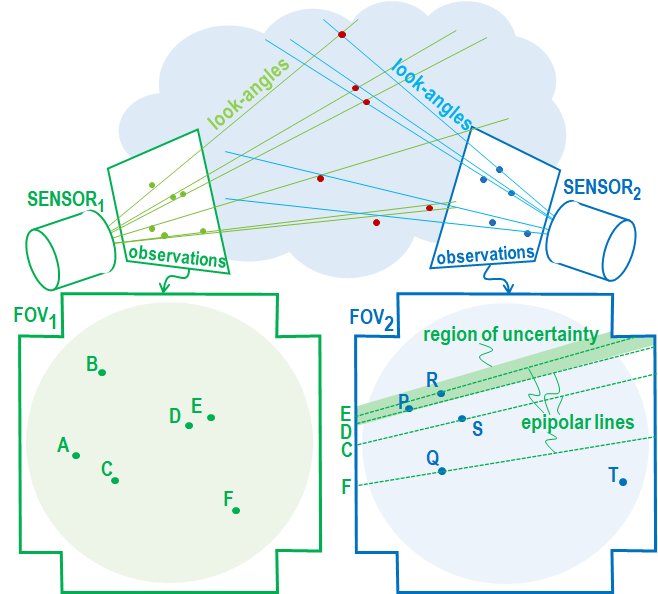
Figure. 3 Line-of-Sight Sensor Fusion
projected into the object cloud. Such a projection is called an epipolar line. Every observation in a sensor’s field-of-view, say FOV1 casts a projected line along the look-angle into fields-of-view of the non-collocated sensors. Each point in FOV1 has a corresponding epipolar line as viewed in another sensor’s field-of-view, say FOV2. Geometry ensures the correctly matched object must lie on this line or within the measurement uncertainty of the sensor. In our problem data set, there were usually multiple objects within the epipolar line’s region of uncertainty. Fortunately, the sensors and objects were moving in a way that resolved this ambiguity. As they moved, the points that fell inside the regions of uncertainty would change. While there were multiple matching candidates at any given time, only one object would remain on or near the epipolar line of the matching object. Unique matches were obtained by repeatedly performing set intersection operations on these object sets for each epipolar line.
Without the details of the sensor locations, motion, pointing direction, and optical configuration, the AI approach would have been computationally costly while producing a high error rate. By including the aforementioned sensor details, the problem was reduced to one of logical set operations and geometric triangulation. The one remaining task for which an AI approach was warranted was the de-termination of the number of objects contained in unresolvable clusters called closely-spaced-objects (CSOs).[6]
3.2 Tank Target Damage Assessment
In the second problem being presented, our task was to determine the level of damage of a main battle tank based on observable effects such as location and col-or of smoke coming from a port or vent, or the direction of the turret or angle of the gun tube. This AI/ML program and related tools was named the Target Damage Assessment System (TDAS). [7]
At the time of this work, it was common practice to train 3-layer neural net-works (NN)s using backpropagation. In early attempts using this approach, we built NNs that worked well most of the time, but occasionally would fail to recognize what seemed to be obvious damage indicators.
After a number of restarts, we realized we needed a way to determine why a NN was failing, but there was no meaningful way to analyze the NN weights to extract the root causes of errors. This led us to develop a different knowledge processing architecture in which we built many smaller NNs, each tasked to report on the presence or absence of a particular feature of interest. We fed the outputs of these NNs into an expert system expressed in a type of knowledge graph (KG) called a conceptual graph,[8] The conceptual graph gave us a means of assessing the level of damage on the tank being evaluated. It also permitted us to determine which element or elements of the input data or outputs of the “one job” NNs was responsible for failures, allowing use to bound the NN detection characteristics.
We referred to this multiple-agent AI application as a Bounded Neural Network (BNN). A typical BNN architecture consisted of a combination of NNs, and KGs as depicted in Figure 4. In addition to these AI agents, the BNN supported the use of grid-style arithmetic calculators permitting statistical calculations and data smoothing operations.
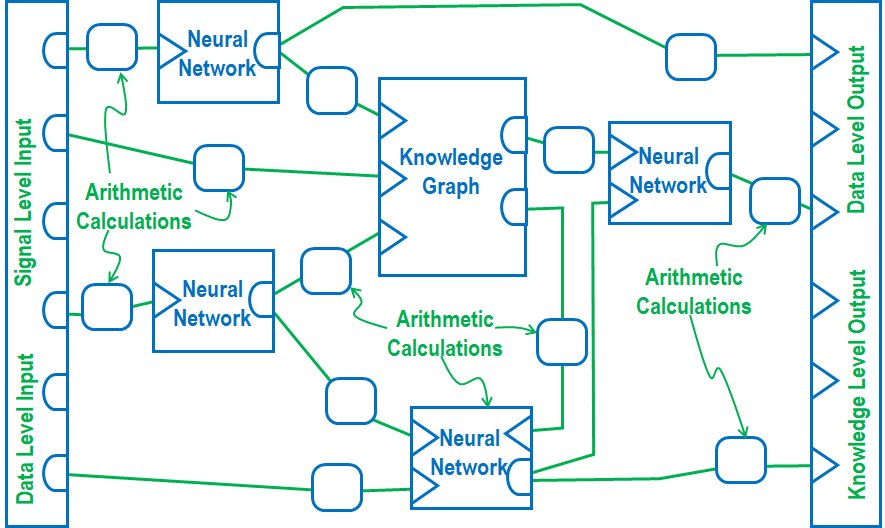
Figure 4. Bounded Neural Network Architecture
The TDAS effort was followed by a related project in which TDAS results on multiple tanks were processed and evaluated by network of higher-level KG agents. This program was named the Battle Damage Assessment System (BDAS), and it was a hierarchical system of systems, containing many TDAS models. The BDAS produced an order of battle on an adversary’s tank column as a decision aid to a battlefield commander. The use of conceptual graphs for the monitors pro-vided us a way to query the models in order to locate and correct errors.
As part of this follow-on work, additional monitoring agents were built and added to our multi-agent AI/ML architecture to include:
Situational Awareness Agent – A component containing the background knowledge about the systems and situation pertinent to the problem being solved. These data are stored in the form of dictionaries and expressed in knowledge graphs.
Situation Understanding Agent – This was our first experience with contextual modeling. A conceptual graph was used to perform sub-graph isomorphisms comparing similar situations. Specifically, this approach sets a similarity measure between newly generated graphs and those in a repository of standard prototypes.
Decision-Making Agent – This agent was built to consolidate NN and KG out-puts which were distributed throughout the BNN completing the decision-making process. At the time of this effort, we closely followed Sowa’s six graph operations.[9] In more recent projects we have expanded the set of graph entities and operations in order to assess AI methods not then realized.[10]
3.3 Hazardous Terrain Detection
In our last example, we discuss a current project addressing hazardous terrain detection. To perform this task, we are combining multiple, open-source, object recognition agents, with a terrain detection agent based on geometry and an agent to track sensor orientation and optical configuration originally employed to sup-port sensor fusion. Although this application is very different, the monitoring agents are essentially the same.
The geometric hazardous terrain detection is based on parallax or the rate of change in position of selected blocks of texture in successive video frames. As shown in Figure 5, a sequence of texture blocks is selected in a frame. A version of optical flow is used to locate the matching texture blocks in the next frame of the video.
The motion of the matching pairs of blocks is analyzed. When there is a sudden change in the rate of motion within a subgroup of texture blocks, it is interpreted as a drop-off, since more distant objects change viewing aspect more slowly than closer ones. When the difference is sufficiently large a rollover hazard is flagged. A machine learning approach can be applied to generalize this method. It is important to understand that the speed of the vehicle as well as the camera settings and video frame rate must be known in order to take advantage of this method. It is also noted that vehicle speed can be used to set the size of the search region for texture block matching, thus reducing computational load.

Figure 5. Tracking texture blocks for parallax-based detection of rollover hazards
In this system, the parallax method is combined with tensor-based object detection depicted in Figure 6. These two methods check and bound each other to improve detection while reducing false alarms. Additional monitoring agents such as the sky-ground agent are included to reject contextually impossible situations.

Figure 6. Tensor-based rollover hazard detection checked by a sky-ground monitoring agent.
While this is a work in progress, we see the hazardous terrain problem as an excellent example of the value of being able to query AI/ML applications with respect to why a particular action was taken from a variety of choices. This is a list of our preliminary findings:
• The repositories for open-source training and testing lack sufficient information about the camera configuration to support verifiable AI.
• Imager-only depth-perception can be implemented spatially using two or more cameras as well as temporally using consecutive video frames.
• We can use a Situational Awareness Agent to capture and eliminate erroneous object detection results that are in conflict with image context.
• We have developed a method of communicating hazards to the user through symbolic compositing onto the driver display.
• A Permanence Agent is needed that maintains awareness of obstacles and other hazard as they move into and out of view near the vehicle.
4 Discussion
We now return to Figure 1 to discuss the importance of monitoring the trans-mission of information over the boundary between the real-world and digital do-mains.
In our first example on sensor fusion, the solution relies on a knowledge of the quality of measurements and the configuration of the sensors that is being transferred at the signal level. In order to implement this algorithm, the size of the region of uncertainty around epipolar lines must be known. This is primarily a function of the resolutions of the sensors. The mathematical projection of the epipolar line requires a knowledge of sensor locations in space, the optical fields-of-view, and the look-angles of the sensors. It also requires the AI system be able to apply the rules of geometry. Finally, the system must have the ability to apply logic operations using knowledge level rules.
The monitoring agents can respond to queries during AI VVT&E, since they are encoded as conceptual graphs that can be evaluated to determine values of the graph entities that led to an error. For example, a mismatch could be due to an object being incorrectly tracked between frames in one of the sensors, or an error could be due to a situation in which the correct matching object fell outside the region of uncertainty for a projected epipolar line. In either case, the monitoring agent can be probed to obtain an explanation.
In our second example, the multiple agent approach was exemplified by generating separate object detection agents for each feature representing a specific type of tank damage. These NN agents passed their results on to the conceptual graph embodying the configuration and damage modes for the adversary tank. When a threshold number of entities in the conceptual graph received values, its output specified a damage level. When the completion of the graph was close to this threshold, TDAS would report results with a lowered confidence level. The user could query the graph to determine the reason for this low confidence value. In such a query, the user and TDAS were communicating at the knowledge level.
In the follow-on effort BDAS introduced a way to generalize by comparing a new partial graph with portions of known graphs. When a newly generated graph matched the sub-graphs of more than one graph in the repository, the element or elements and their values that would resolve this ambiguity were requested by the AI system. Communication involving discovery of a generalization is at the con-textual level.
Our third example was a multiple agent AI/ML application that monitors boundary transitions at all levels. Edge processing of the video to support image stitching and registration is occurring at the signal level. Simultaneously, a panoramic view is output to the user at the signal level. Camera configuration and kinematics communication is occurring at the data level. Situational Awareness in the form of compositing onto the driver display is occurring at the knowledge level and first-principles and permanency agents are maintaining an understanding of potential hazards at the contextual level.
5 Future Direction
In consideration of the increasing emphasis on the need for AI VVT&E, we are working to make our hazardous terrain detection system a demonstrator program for the feasibility of boundary monitoring to support explainable and verifiable AI/ML.
Possibly the biggest challenge for AI application builders is the problem of validation. It is relatively easy to validate a non-AI (procedural) application by pre-mapping possible input states to desired output states. Examples of this kind of programming are common rule-based expert systems (If A then B) and other forms of finite state machines where the correct output state for every possible in-put state is pre-determined by domain experts. To truly be considered artificial intelligence however, an application must employ a technique that adapts and learns how to respond to new or unexpected states. When an unanticipated input state does occur, the code must first, be able to recognize that an unanticipated state has occurred and second, be able to assign a valid output state to it. In an unsupervised system there is no easy way to validate the program-generated output state. In the past, the solution was to add a human in the loop and do supervised learning, al-lowing the human expert to choose the output state for the program. Although this approach works, it does not allow the program to autonomously execute decision-making in real time.
It is our intent to replace the human expert, where feasible, with monitoring agents each with low probability of false alarm and high probability of each agent successfully performing their “one job”. The collaboration of these agents catches contextually impossible or improbable conditions lowering the priority of the anomalous AI/ML element and raising the priority of the nominal ones.
In future research we plan to codify universal monitoring agents to address basic laws of physics across multiple disciplines and to build the numeric interfaces to transform various modalities of sensor measurements into forms compatible with the CG entities holding the agent knowledge. We plan to expand and standardize our geometric and logical operation monitoring agents with the goal of including them in the repository of open-source AI tools. Our overarching objective is to develop an effective contextual AI/ML approach for serious real-world applications.
While we have been retooling, refining, and expanding the capabilities of our AI/ML repository over 25 years, we recognize that solving the challenge for AI VVT&E is becoming more urgent as AI methods are integrated into greater numbers of safety-critical applications. We have recently come to realize that the AI community needs to spend as much time sharing and discussing our AI failures as we do publishing our successes. Otherwise, the rate at which we deploy fully automated systems will continue to outpace our ability to ensure their efficacy and safety.
References
1. Castillo, Michelle. “Why Did Watson Think Toronto Is a U.S. City on ‘Jeopardy’?” TIME: Gaming & Culture, TIME USA, LLC, 16 Feb. 2011, https://techland.time.com/2011/02/16/why-did-watson-think-toronto-is-a-u-s-city-on-jeopardy/.
2. Tarraf, Danielle C., et al. “How Well Is DoD Positioned for AI?” RAND Corporation, The RAND Corporation, Santa Monica, Calif., 17 Dec. 2019, www.rand.org/pubs/research_reports/RR4229.html.
3. Turpin, Rob, et al. “MACHINE LEARNING AI IN MEDICAL DEVICES: Adapting Regulatory Frameworks and Standards to Ensure Safety and Performance.” Ethos, AAMI & BSI, 2020, https://www.ethos.co.im/wp-content/uploads/2020/11/MACHINE-LEARNING-AI-IN-MEDICAL-DEVICES-ADAPTING-REGULATORY-FRAMEWORKS-AND-STANDARDS-TO-ENSURE-SAFETY-AND-PERFORMANCE-2020-AAMI-and-BSI.pdf.
4. Canis, Bill. “Issues in Autonomous Vehicle Testing and Deployment.” Congressional Research Service, U.S. Government, 23 Apr. 2021, https://crsreports.congress.gov/product/pdf/R/R45985.
5. Pilgrim, Robert A, et al. “A New Algorithm for Multiple Sensor Data Fusion for Strategic Applications”. Chicago, Ill.: GACIAC, IIT Research Institute, 1989., 5 Apr. 1989.
6. Hall, Robert, et al. “Detection of Closely-Spaced Objects Using Radial Variance”, Proceedings of the SPIE, 1989.
7. Bevilacqua, Andrew, et al. “Development and Demonstration of a Multi-Level Neural Network for Battle Damage Assessment” Final Technical Report Contract #DAAL00-94-C0040, Research Sponsored by: The Army Research Laboratory, Adelphi, MD. June 1995.
8. Sowa, J.F., et al. “Conceptual Structures. Information Processing in Mind and Machine”, Addison-Wesley Longman Publishing Co, Boston MA, 1984.
9. Sowa, J. F. Semantic Networks. Encyclopedia of Cognitive Science. doi:10.1002/0470018860.s00065, January 2006.
10. Bevilacqua, Andrew, et al. Applying Complex Reasoning Tools to Mission Effectiveness. Integrated Design and Process Technology, IDPT, Society for De-sign and Process Science, June 2006.
Presented at the 23rd International Conference on Artificial Intelligence (ICAI 2021) to be published in Transactions on Computational Science, Computational Intelligence, Springer Nature, 2021